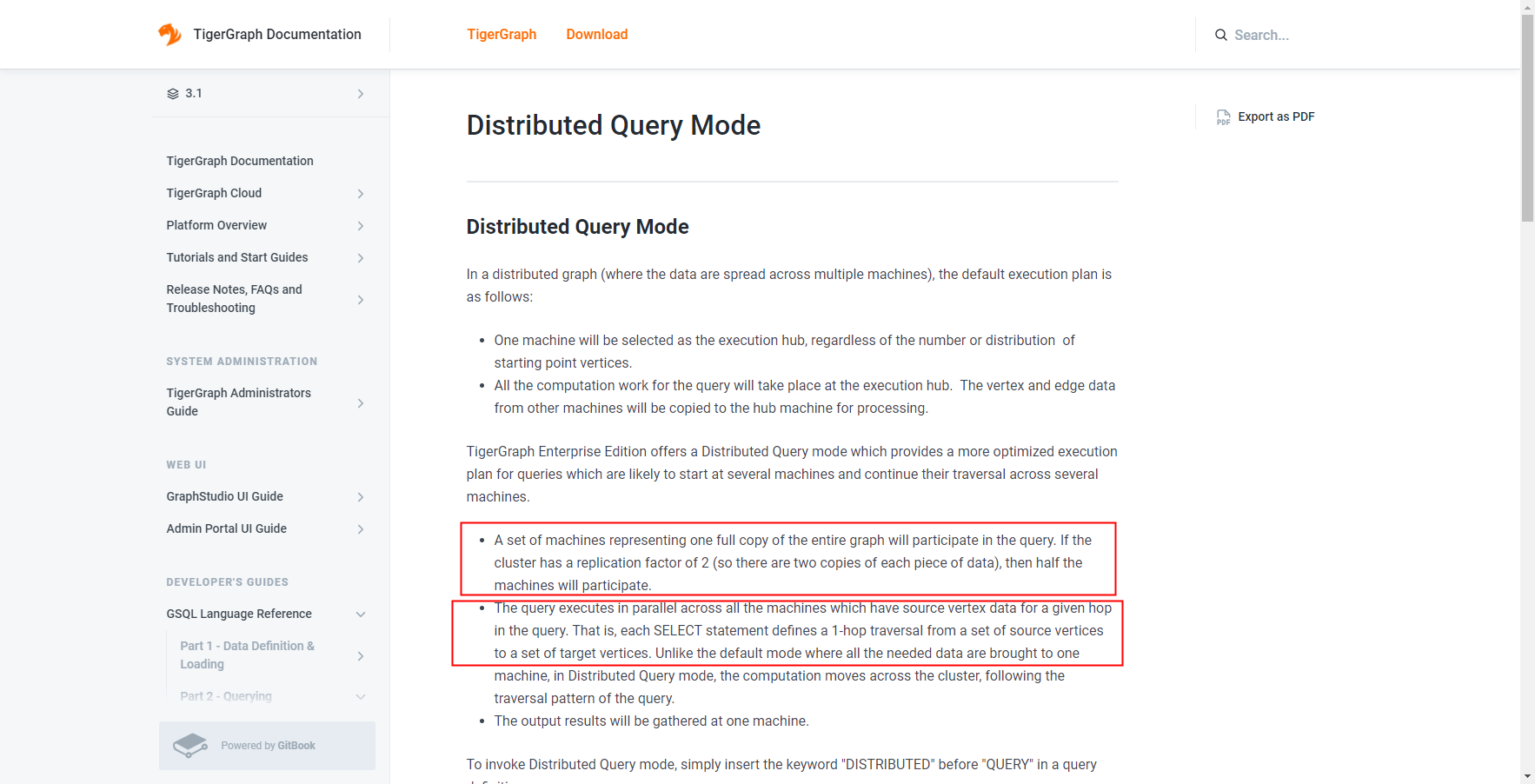
I have the following questions about 3.1 “ Distributed Query Mode” doc:
- How many machines participate in distributed query? Is it one group or one ? Is it related to Replication Factor ?
- What does “SELECT statement” mean here ?
The number of machines participating in a distributed query = your database’s distributed factor. If you have configured your database to spread data across 5 servers, then 5 will work on the compute-intensive* aspects of a distributed mode query.
Distribution factor is separate from replication factor. You could configure the same cluster with a replication factor of 2, meaning there are 2 complete copies of the data. You would have a total of 5 x 2 = 10 servers. A distributed mode read query only needs to see one copy of the data, so it only works with 5 of them.
*You will get the same answer to the query if you don’t run it in distributed mode. The query will need to talk to the same servers, but the computational work will be centered around just one server. In non-distributed mode, remote servers send requested data to that query’s lead server and let it do the heavy compute and aggregation work.
In GSQL, just like in SQL, the core command for reading data from the database is the SELECT command/statement. You learn about SELECT in GSQL 101.
Thank you for your reply.
I don’t understand “total of 5 x 2 = 10 servers”. If I configure a 5-node cluster with a Replication Factor of 2, my understanding is that I only have 5 machines working, why say “10 servers”?How are the two complete pieces of data for this cluster distributed? Is it evenly distributed across all 5 machines?
The distribution factor is across one copy of the data = how many servers you need if you want only one copy of the data. That constitutes one logical copy of the database. When the system replicates, it replicates the dataset, which requires an additional set of servers. You can change the configuration to add more replicas, but that will require adding more servers.
The automatic data partitioning algorithm built into TigerGraph tries to keep the data evenly distributed across the servers.
Let’s say that we have a cluster of 3 machines with replication factor of 3 (and distribution factor of 1).
Meaning, each machine stores 100% of the data.
And let’s say I’m running a “full graph scan” algorithm (such as connected components) in distributed mode.
How many machines will execute the algorithm?
On one hand, judging by your explanation, the distribution factor is 1, so 1 machine will run the algorithm.
On the other hand, in the documentation, it does say that:
Distributed Query Mode is likely to improve the performance of a query if the query:
- Starts at a very large set of starting point vertices.
You need to start from “Do I have a distributed system?”. This documentation page begins with “In a distributed graph (where the data are spread across multiple machines)…”
In your 1x3 configuration example, your data are not spread out. You do not have a distributed system, so none of this page applies. You should not run queries in Distributed mode.