Hi TG community,
I am trying to print to a CSV but it is not saving. I am working with the 3.1.6 installed version of TG (I know this needs an update but according to the old documentation it should still work).
My code is below. I have followed the example in the documentation. Let me know if there is something missing:
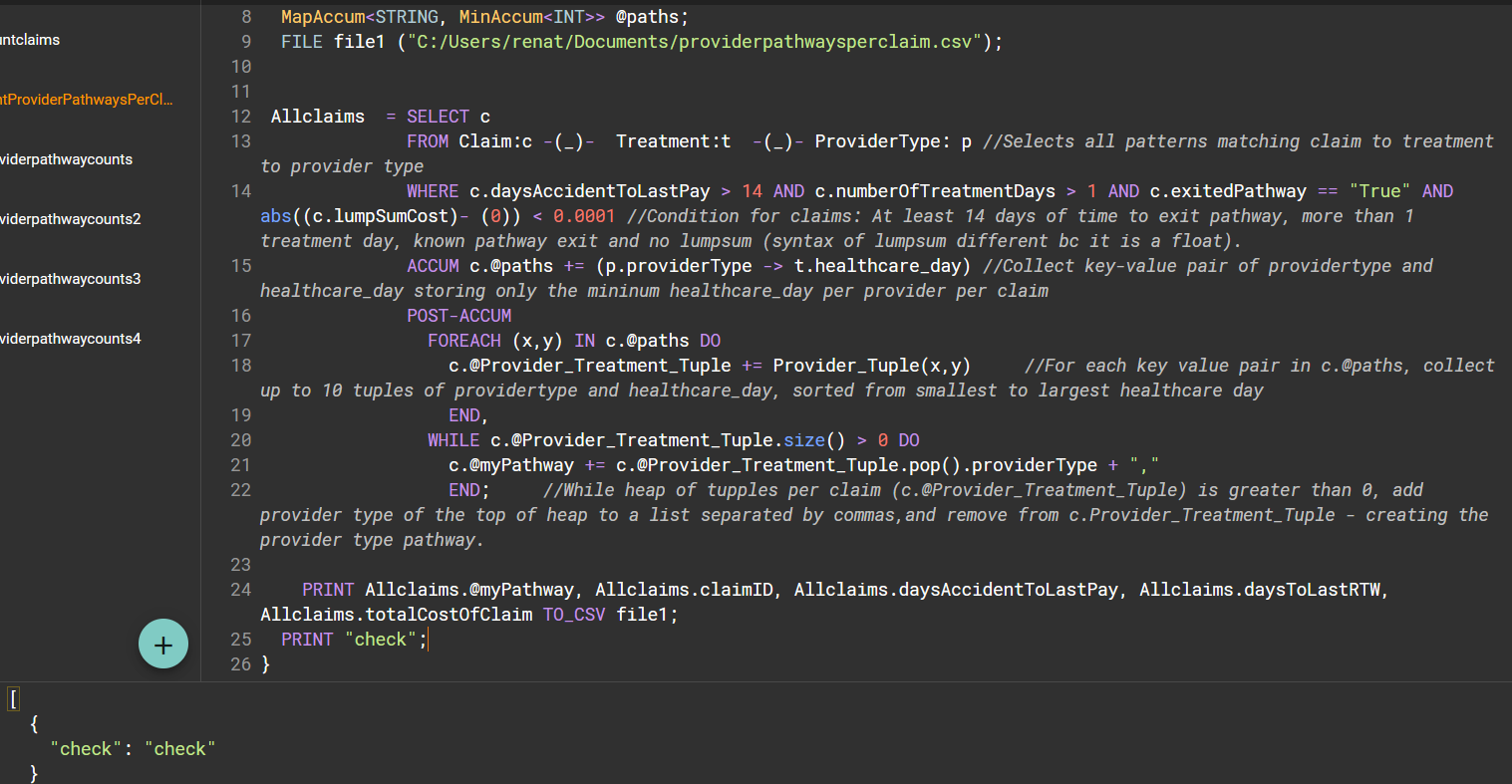
CREATE QUERY PrintProviderPathwaysPerClaim(/* Parameters here */) FOR GRAPH ACC_mTBI_pathway SYNTAX V2 {
TYPEDEF tuple<STRING providerType, INT healthcare_day> Provider_Tuple;
HeapAccum<Provider_Tuple>(10, healthcare_day ASC) @Provider_Treatment_Tuple;
SumAccum<STRING> @myPathway;
MapAccum<STRING, INT> @@pathways;
MapAccum<STRING, MinAccum<INT>> @paths;
FILE file1 ("C:/Users/renat/Documents/providerpathwaysperclaim.csv");
Allclaims = SELECT c
FROM Claim:c -(_)- Treatment:t -(_)- ProviderType: p //Selects all patterns matching claim to treatment to provider type
WHERE c.daysAccidentToLastPay > 14 AND c.numberOfTreatmentDays > 1 AND c.exitedPathway == "True" AND abs((c.lumpSumCost)- (0)) < 0.0001 //Condition for claims: At least 14 days of time to exit pathway, more than 1 treatment day, known pathway exit and no lumpsum (syntax of lumpsum different bc it is a float).
ACCUM c.@paths += (p.providerType -> t.healthcare_day) //Collect key-value pair of providertype and healthcare_day storing only the mininum healthcare_day per provider per claim
POST-ACCUM
FOREACH (x,y) IN c.@paths DO
c.@Provider_Treatment_Tuple += Provider_Tuple(x,y) //For each key value pair in c.@paths, collect up to 10 tuples of providertype and healthcare_day, sorted from smallest to largest healthcare day
END,
WHILE c.@Provider_Treatment_Tuple.size() > 0 DO
c.@myPathway += c.@Provider_Treatment_Tuple.pop().providerType + ","
END; //While heap of tupples per claim (c.@Provider_Treatment_Tuple) is greater than 0, add provider type of the top of heap to a list separated by commas,and remove from c.Provider_Treatment_Tuple - creating the provider type pathway.
PRINT Allclaims.@myPathway, Allclaims.claimID, Allclaims.daysAccidentToLastPay, Allclaims.daysToLastRTW, Allclaims.totalCostOfClaim TO_CSV file1;
}
Thanks for the continued support!
Renata
Hi @renatagot!
What is the current output you are getting if you are getting any? My first thought is that your file1 path is leading to a .csv file FILE file1 ("C:/Users/renat/Documents/providerpathwaysperclaim.csv");, but in our documentation, it looks like it should be written to a .txt file seen in this example.
Once the information saved to the text file should be in csv format/can be converted into a .csv file seen here.
Let me know if this helps!
Hi @McKenzie_Steenson,
Thanks for your quick response!
The output is empty. I added a print line at the end to make sure that the query was running. Here is the output:
Based on this post .csv should be working too. But I did try .txt and it was also empty. What is the correct way to start the file path? Since all the examples only show the end of the file path, maybe the error comes from that?
@renatagot can you go to the directory location you want the file to land. Then run pwd to grab the file path.
**tigergraph@box:~$ pwd
/home/tigergraph
Then copy that path into FILE file1 ("/home/tigergraph/print_example_file.csv"); with your file name.
Full Example:
CREATE QUERY GetConnectedToCSV(STRING pName) FOR GRAPH Linkedin SYNTAX V2 {
TYPEDEF TUPLE <STRING TigerGraph_Employee, STRING Connected_To, STRING Position, STRING Company, STRING Email> PPL;
ListAccum<PPL> @@pplList;
STRING myParam;
FILE file1 ("/home/tigergraph/print_example_file.csv");
myParam = "%" + pName + "%";
S1 = SELECT p FROM Person:s -(CONNECTED_TO:e)-Person:p
WHERE s.id LIKE myParam
ACCUM @@pplList += PPL(p.FullName, s.FullName, s.Position, s.Company, s.Email);
PRINT @@pplList TO_CSV file1;
}
1 Like
Hi @Jon_Herke,
I have done the windows equivalent:

and pasted into FILE file1 as per your example. Still not working. Have you heard of windows users having issues with this? I need to print to csv to run stats (Kruskal-Wallis) for my project so am really stuck without being able to export output to use in python. Are there any ways to save the json output as is so that I can convert it afterwards?
@renatagot Ahh I see. TigerGraph will be able to export the CSV file into the operating system it’s being ran on. If you’re using a docker image the location of the file export will be inside the machine that is running TigerGraph.
You might be able to export the file into your Docker environment and then use Docker Desktop to retrieve the file to your local Windows machine.
2 Likes
@Jon_Herke, this explains it! I tried looking into what the file directory would be and couldn’t find anything. Will look into this more myself but if you already have an idea and could point me in the right direction that would be awesome. Thanks again!
1 Like
@renatagot
You should be able to access your Docker Container Server by using SSH. Here is a sample guide to using SSH with Docker. How to SSH into a Running Docker Container and Run Commands
Once you are into your server. Run sudo su tigergraph which will switch your user to the tigergraph user account.
Then use the command cd and hit enter which will bring you to /home/tigergraph. to confirm this run
pwd to check your file path.
2 Likes