Loading graphs where there is often multiple edges with the same source id and destination id (with different attributes). These edges only appear once in the database. Is there any way to set a primary key on edges? Or is there any other solution so that all the edges appear in the database?
1 Like
Alexey,
Very good question.
Currently, GSQL does not support multiple edge instances that share the same pair of source and target vertex pair. This is one feature on our roadmap.
However, there is a workaround.
You can create one edge instance with attribute of List type, where T is your original edge scalar attribute type. See List attribute type here
https://docs.tigergraph.com/dev/gsql-ref/querying/data-types#vertex-and-edge-attribute-types
To load a list of values into a List attribute, you can follow the section
“Loading a LIST or SET Attribute”
For example, your original edge is
CREATE DIRECTED EDGE Friendship (FROM person, TO person, connect_time DATETIME);
You can create
CREATE DIRECTED EDGE Friendship (FROM person, TO person, connect_time LIST<DATETIME>);
and load multiple edge instances into one edge instance.
Hope this helps.
Mingxi
Hi,
When do you guys plan on making this available?
Thanks!
@AB84 We don’t have a hard date when this will be available. All (nice-to-have) feature requests are prioritized based on customer needs. If there is a customer that this feature is mandatory its priority would be bumped up. Is this feature mandatory for your use case?
@Jon_Herke yes! I think we need this feature.
The use-case that I’m working on right now is about building relationships (with the help of a graph DB hopefully) among customer activities.
Each activity is identified by a number. I’ll build how one activity relates to other in code (using Java) and persist that relationship to graph DB after aggregating each day’s activities.
So here’s an overview of interactions:
[4,2,7,4,12,4,53,34][occurrence_count:1000, date:2020-01-01]
[5,67,8,9,12,4,5,7,8][occurrence_count:4000, date:2020-01-02]
If you look at 12,4 for example, I need to be able to draw two arrows that goes from 12 to 4.
We deal with millions of interactions. So ideally it’d nice to be able to handle that volume with distinct edges. This is possible in Neo4j, but the reason that I’m staying away from that is it’s too slow 
If you guys can prioritize this, that’d be great!
Hi @Jon_Herke, any update on this?
Thanks
Hi @AB84 are you working with anyone internally as it relates to your TigerGraph? If yes, I can reach out to them and our product team to see what can be done or get some clarification. You can direct message me on here by clicking on my name @Jon_Herke.
So id’s on edges is very much blue-sky as I understand it. Certainly not in the next major release 3.x.
The most generic way to model this is to substitute an edge-vertex-edge combination as a pseudo-edge.
As an aside, this is modelling a hyper-graph, in that hyper-edges can link to other hyper-edges, and/or multiple vertices.
So, for example, augmenting your interactions with a key:
[4,2,7,4, **12,4** ,53,34][occurrence_count:1000, date:2020-01-01, occurence_key: A001]
[5,67,8,9, **12,4** ,5,7,8][occurrence_count:4000, date:2020-01-02, occurence_key: A002 ]
You could have Users, Interactions as vertex types.
The graph structure would look like:
User-(User2Interaction)->Interaction-(Interaction2User)->User
I’m compounding the keys:
You would insert Users: 12, 4
You would insert Interactions: A001-12-4, A002-12-4
You would insert User2Interaction: (12, A001-12-4), (12, A002-12-4)
You would insert Interaction2User: (A001-12-4, 4), (A002-12-4, 4)
If you wanted to hyper-graph it with an Occurrence you could too:
Vertex: Occurence
Edge: Occurrence2Interaction
Then insert Occurence: A001, A002
Insert Occurrence2Interaction: (A001, A001-12-4),...,(A002, A002-12-4),...
Hopefully that is helpful. If anything is unclear (or just doesn’t fit the problem!) let me know.
2 Likes
I think this would make my problem a lot easier too. (@Steven is my go to person, just FYI.).
I like rik’s suggestion though, thanks! I think that will work in my case.
Jon’s above suggestion wouldn’t work because the data in question is a MAP, and there’s no easy way to create a list of maps in TigerGraph (without resorting to string serialization).
I second this request.
My use case also calls for multiple edges between two distinct vertices - exactly as described here.
1 Like
I think this should not be seen as a nice-to-have but rather as a must-have. In order to compete with other solutions this must allow visually exploration of the graphs.
Only displaying one single edge between to vertices leads to missinterpretations. I am dealing with banking wire transactions and have, let’s say an account A making multiple transactions to account B. On another example I have an account C making only one single transaction to account B for the period of analysis.
Visually the network will be displayed the same way both for accounts A and C, both connected to Account B with a single edge and there is no way in telling wich connections are “stronger”. This may not be the purpose of this tool but is typically the first exposure an analyst as to the data.
@bon_vivant Let me check in with the product team on the status of this request.
As for transactions I typically model them as an event having a distinct vertex of their own.
Schema Example:
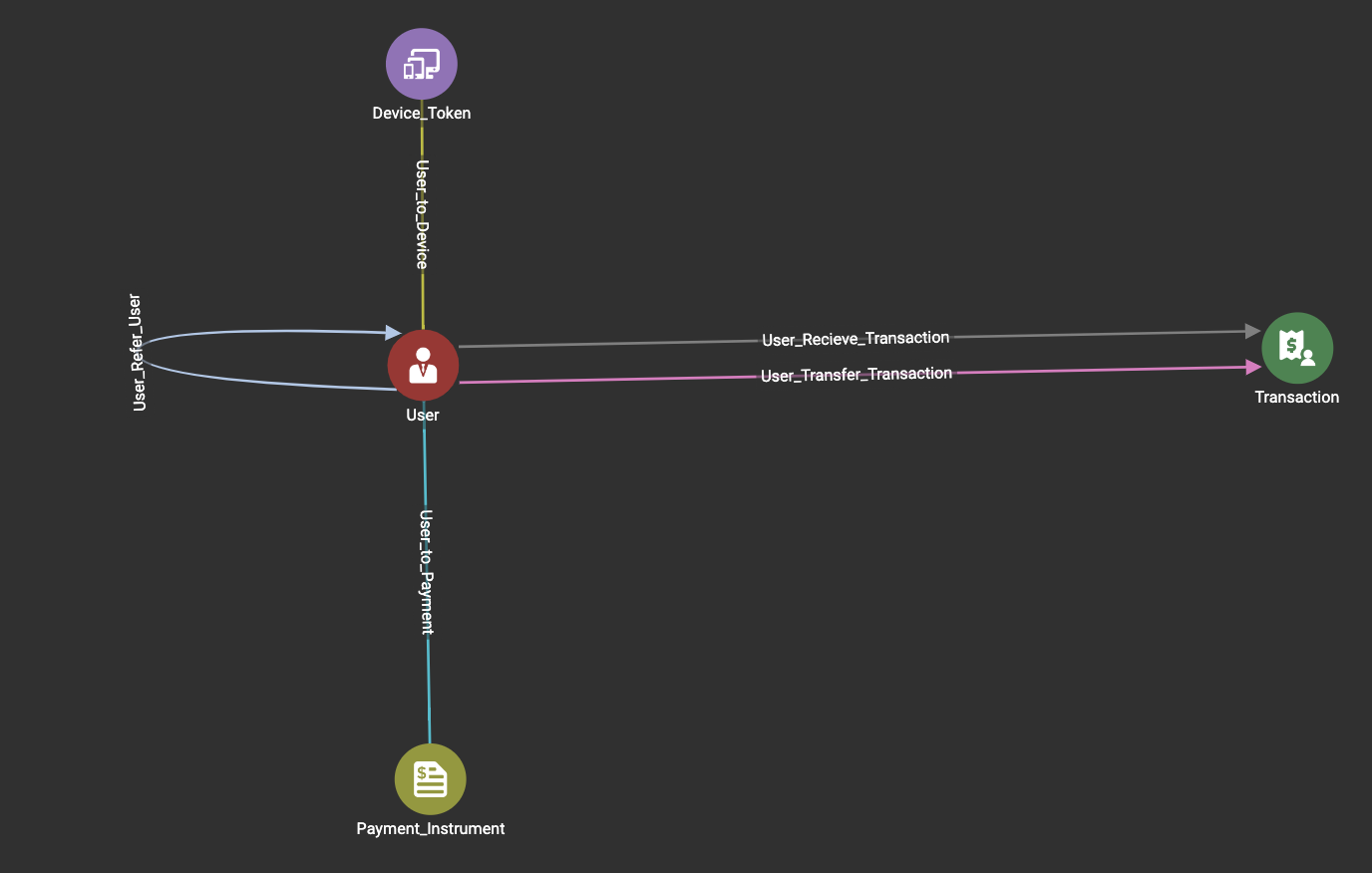
Tx Circle Detection:
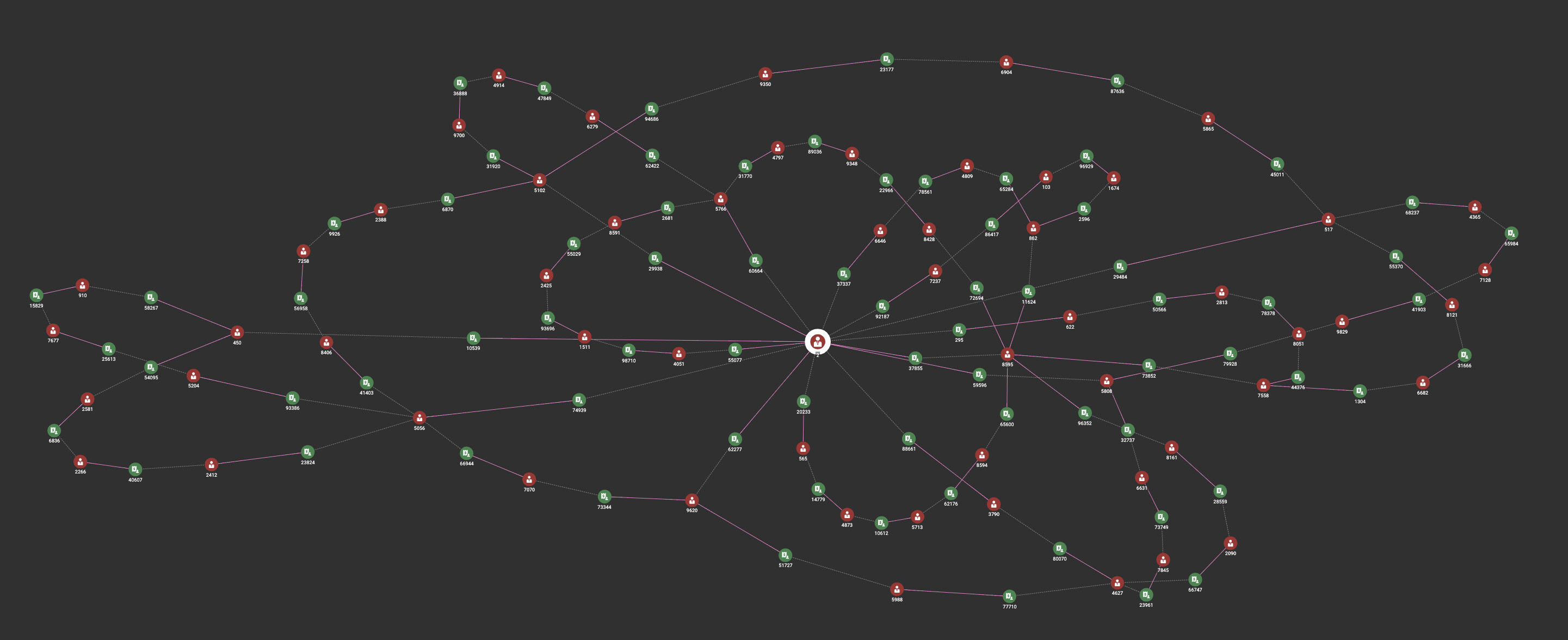
Screenshots are from the TigerGraph test drive:
https://antifraud-testdrive.tigergraph.com:44240/#/home
1 Like
While it is not possible to have multi-edge graphs, do you know if it is more advantageous, in terms of generic algorithm efficiency, to use a list of attributes on the edge or to create an intermediate node that represents the collection of attributes? Thank you!
There is a new feature called Edge Discriminator, which enables the multi-edge implementation - and to answer your question, I still prefer using attributes on the edge when possible to avoid having intermediate nodes.
3 Likes