Hi,
I’m trying to load nodes from a parquet file from S3, which was created by AWS Athena.
I am able to run the loading job successfully, however the node IDs and attributes don’t get populated correctly. It seems to me that there is some mismatch between the parquet format generate by Athena and what is supported by Tigergraph, however I can’t find any documentation on the available serialization/deserialization options supported by either platform (AWS Athena and Tigergraph). As far as I’m aware Athena uses the Hive Parquet SerDe v1.2.2: Parquet SerDe - Amazon Athena
I am specifying gzip compression on both sides.
Here’s a screenshot from GraphStudio highlighting the issue with the created nodes:
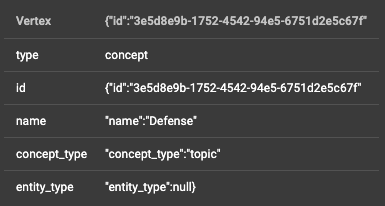
Here are the S3 file configuration and loading job definition that I used for reference:
{
"file.uris": "s3://path/to/athena/parquet/table",
"file.recursive": true,
"file.reader.type": "parquet",
"file.reader.text.archive.type": "gzip"
}
CREATE LOADING JOB s3_parquet_test FOR GRAPH concepts {
DEFINE FILENAME nodes_file = "$s3_graph:/home/tigergraph/tigergraph/config/s3/s3-file-config.json";
DEFINE HEADER nodes_header = "id", "name", "concept_type", "entity_type";
LOAD nodes_file TO VERTEX concept VALUES ($"id", $"name", $"concept_type", $"entity_type")
USING USER_DEFINED_HEADER="nodes_header";
}