Hi from TG community,
I am new to GSQL and need some guidance on where to get started for what I would like to do.
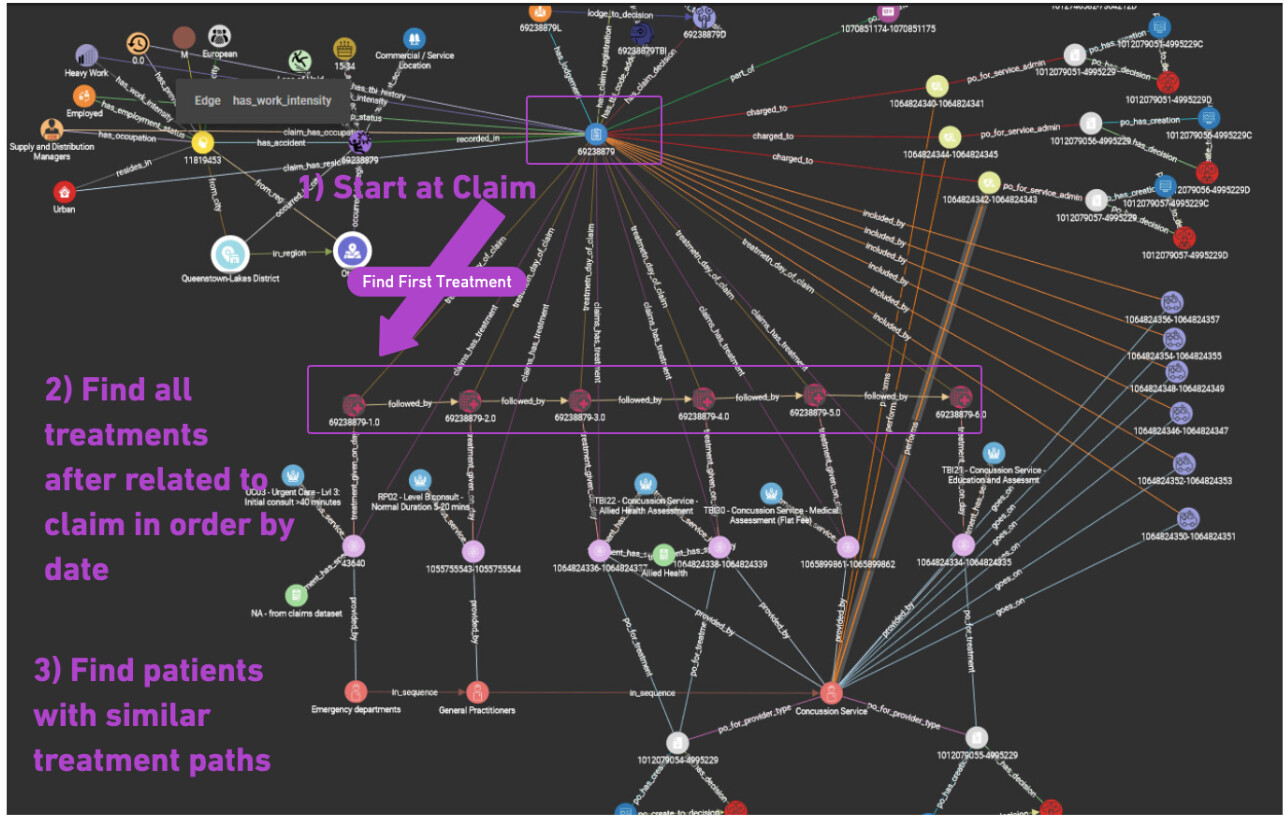
As you can see from the screenshot of my graph, I am working with patient data (yellow vertex on the left) who have claims (blue vertex in the middle) for an injury (purple vertex between the two) and a healthcare provider pathway (in this claim example: Emergency Department → General Practitioners → concussion services). I have ~55,000 claims and each claim has a provider pathway. I would like to filter my graph for certain characteristics (e.g. accident date to first appointment date < 3 days) and then query my graph to return the 10 most common provider pathways. My next step would be to then compare costs of these pathways.
Can anyone provide me with a high level logic of the steps I would take in my query? The main point that I am stuck on is how to return the provider pathway for each claim and then return the x most common. I will figure out details and troubleshoot the query myself but am stuck on where to start.
Thanks in advance,
Renata
@renatagot We have weekly GSQL session with the community on Discord. The next one is next Tuesday 9:30am CST. Would you be able to make it to the session? If not we can try to work through this over the tread.
To help us better understand the data and what is the “provider path”? Could you walk us through the image you provided above. Are you looking to do something like this?
Hi Jon, i will be there for the session!
Steps 1 and 2 are correct (step 2 is find all treatment days related to claim ordered by date).
Step 3 is to find the provider sequence related to the step 2.
The idea is to do this for all claims to find the most common treatment provider sequence.
Step 4 would be to find the average/median cost of each treatment provider sequence.
I hope that makes sense, if not i will do my best to explain on the call in discord.
Thanks!
This may be useful to you, its a technique I have used to find common patterns where sequence matters. You may be able to modify this to suit your needs. The string of event in your case could be a specific provider, or provider specialty, or whatever you choose.
This example produces a comma separate list of each unique sequence and the number of times that sequence occurred. All the interesting stuff happens in the POST-ACCUM clause
TYPEDEF tuple<STRING event, INT eventDay> jEvent;
HeapAccum<jEvent>(10, eventDay ASC) @topEvents;
SumAccum<STRING> @myPathway;
MapAccum<STRING, INT> @@pathways;
MapAccum<STRING, MinAccum<INT>> @paths;
/* determine set of claims to process */
AllClaims = SELECT c FROM ClaimSet:c -(_>)- Treatment:t -(_>)- Provider: p
WHERE t.treatmentType in myGroup
ACCUM c.@paths += (p.providerType -> datetime_to_epoch(t.serviceDate)/86400)
POST-ACCUM
FOREACH (x,y) IN c.@paths DO
c.@topEvents += jEvent(x,y)
END,
WHILE c.@topEvents.size() > 0 DO
c.@myPathway += c.@topEvents.pop().event + ","
END,
@@pathways += (c.@myPathway -> 1);
PRINT @@pathways;
2 Likes
This is very helpful, thanks a lot Mark!
Hi team,
I have read through the documentation to understand the code and have adapted it to my case. This is what I have below. It is returning a count for one empty provider sequence. I think that the issue may be in the Provider_tuple(x,y) in the 2nd line of the post accum because in other examples I saw something such as Provider_tuple(p.providerType, t.healthcare_day) which would access the attributes from the relevant vertices. However, I get an error when I do this: “postaccum clause is not local”. I think this is because I am using more than one alias per post accum. Any thoughts on what could be going wrong or how to fix it? Thanks in advance.
CREATE QUERY Providerpathwaycounts(/* Parameters here */) FOR GRAPH ACC_mTBI_pathway SYNTAX v2 {
TYPEDEF tuple<STRING providerType, INT healthcare_day> Provider_Tuple;
HeapAccum<Provider_Tuple>(10, healthcare_day ASC) @Provider_Treatment_Tuple;
SumAccum<STRING> @myPathway;
MapAccum<STRING, INT> @@pathways;
MapAccum<STRING, MinAccum<INT>> @paths;
AllClaims = SELECT c FROM Claim:c -(_)- Treatment:t -(_)- ProviderType: p //Selects all patterns matching claim to treatment to provider type
WHERE c.daysAccidentToLastPay >= 14 AND c.numberOfTreatmentDays > 1 AND c.exitedPathway == "True" //Condition for claims: At least 14 days of time to exit pathway, more than 1 treatment day and known pathway exit
ACCUM c.@paths += (p.providerType -> datetime_to_epoch(t.service_date)/86400) //Collect key-value pair of providertype and days since Jan 1 1970 of treatment service date, storing only the mininum number of days to treatment date since 1970Jan1
POST-ACCUM
FOREACH (x,y) IN c.@paths DO
c.@Provider_Treatment_Tuple += Provider_Tuple(x,y) //For each key value pair in c.@paths, collect up to 10 tuples of providertype and healthcare_day, sorted from smallest to largest healthcare day
END,
WHILE c.@Provider_Treatment_Tuple.size() > 0 DO
c.@myPathway += c.@Provider_Treatment_Tuple.pop().providerType + "," //While heap of tupples per claim (c.@paths) is greater than 0, add provider type of the top of heap to a list separated by commas, creating the provider type pathways.
END,
@@pathways += (c.@myPathway -> 1); //Create a list of each unique provider type pathway and the number of times the pathway occurrs in the dataset
PRINT @@pathways;
}

Hi TG community,
I was able to get the above code to work with help from the office hours team, but the output is not showing providers that have already appeared once after another provider e.g. the second GP occurrence in this sequence: ED, GP, Physio, GP
I am trying to tackle this problem a different way and here is what I have:
CREATE QUERY Providerpathwaycounts3(/* Parameters here */) FOR GRAPH ACC_mTBI_pathway SYNTAX v2 {
SumAccum<STRING> @providerSequence;
MapAccum<STRING, INT> @@pathwayCount;
Pattern = SELECT c
FROM Claim:c -(claims_has_treatment)- Treatment:t -(provided_by)- ProviderType:p -(in_sequence>*) - ProviderType:pl
WHERE c.daysAccidentToLastPay >= 14 AND c.numberOfTreatmentDays > 1 AND c.exitedPathway == "True" AND t.healthcare_day == 1
ACCUM c.@providerSequence += pl.providerType + ","
POST-ACCUM @@pathwayCount += (c.@providerSequence -> 1);
PRINT @@pathwayCount;
}
I am getting “The query response size is 96MB, which exceeds limit 32MB.” as the output. The correct output definitely shouldn’t be this big so there is something wrong in the code that I can’t pick out. The goal is to return the sequence of provider types for each claimand the number of times they occur in the dataset. If the output could be sorted from highest to lowest occurrence that would be ideal.
Here is the graph design
You are correct that my first version would not have repeats of providers. But that should be easy to change
TYPEDEF tuple<STRING event, INT eventDay> jEvent;
HeapAccum<jEvent>(100, eventDay ASC) @topEvents;
SumAccum<STRING> @myPathway;
MapAccum<STRING, INT> @@pathways;
MapAccum<STRING, MinAccum<INT>> @paths;
/* determine set of claims to process */
AllClaims = SELECT c FROM ClaimSet:c -(_>)- Treatment:t -(_>)- Provider: p
WHERE t.treatmentType in myGroup
ACCUM c.@topEvents += jEvent(p.providerType , datetime_to_epoch(t.serviceDate)/86400)
POST-ACCUM
WHILE c.@topEvents.size() > 0 DO
c.@myPathway += c.@topEvents.pop().event + ","
END,
@@pathways += (c.@myPathway -> 1);
PRINT @@pathways;
Hi Mark,
Thank you for the response.
I have tried using this method but it then returns repeated providers even if there is not another provider type in between. For example:
If the sequence of treatments causes the provider sequence to be:
GP, GP, GP, Physio, Physio, GP
The latest code would return this exact sequence while the original code would return:
GP, Physio
What I would like is for it to only show repeated providers if the last provider is not the same:
GP, Physio, GP
For this to happen, I would need a way to compare the current provider with the last provider and only include it in the heap if current provider != to last provider. I discussed this with the office hours team but we couldn’t find a way to do this (the tick operator doesn’t work).
This is why I am now trying to utilise the sequence in the graph design itself, which contains the sequence in the way that I want it (see my last post). However, there is something wrong with the code I tried (last post) as it isn’t outputting correctly. After reading all the documentation, I can’t figure out what it is.
If you have any thoughts on how to make either code return the desired result that would be great.
Thank you again.
Update: I no longer need the provider sequence as described above. No help needed, Thanks!
1 Like