
Hi Everyone,
I apologize for the lengthy post but I wanted to make sure the issue and desired results were clear. I’m open to any and all suggestions and would happily jump on a call to discuss in detail. I’m tried a few different schema designs and countless queries but I haven’t found anything that’s acceptable. Here we go…
Attachment
Contains the graph schema and the query.
Screen Shots
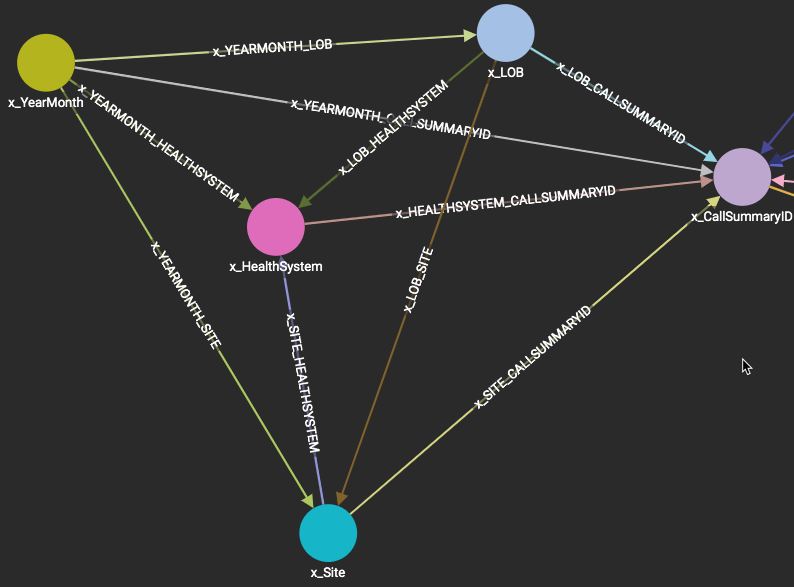
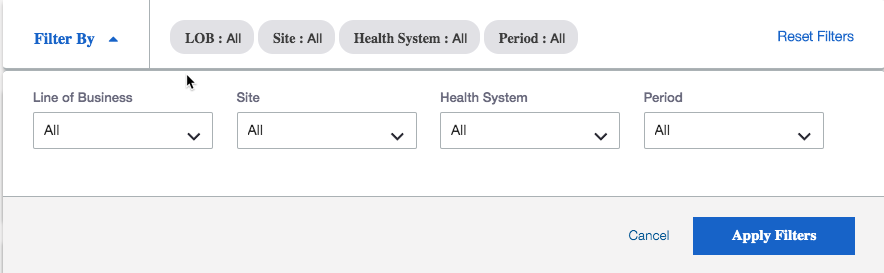
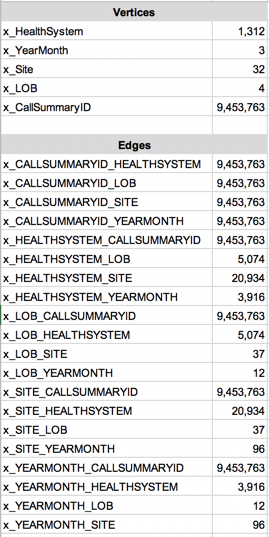
First, is the graph schema. Second, is the UI parameter section. Third, is the query. Fourth, is the current size of the graph.
NOTE: This graph has many more vertices and edges but I don’t believe they are needed for this issue. This graph currently contains 3 months of data (2019 Jan-Mar). We plan on loading at least all of 2018 and 2019 YTD. Assume the graph will be at least 6 times it’s current size if fully populated excluding the vertices and edges not mentioned in this post.
Background
This query is used in a UI where the user has 4 filtering options (YearMonth, LOB, Site and HealthSystem). If a user selects a LOB then only the YearMonth, HealthSystem and Site for that LOB are available for that user to continue their filtering. Very similar to excel-like filtering where the other filters will update based on your selection. This is what lines 2-44 achieve. The end results of this is a PRINT statement (line 46) that contains all available options in the UI filters. Every time the user selects a parameter value and clicks off, the UI calls the query and updates the available values. The UI can send no parameters to the query or a list for each one. We have not had any issues with this and if all values are selected or no parameters are passed to the query, the query will typically execute in 40 ms or under. However, I’m always open to suggestions.
When the user is finished selecting their filters, they will click the Apply Filters button in the UI. This button will execute the query with the apply parameter of TRUE. This will run the coding between line 48 and 71. The end result of this IF statement is a series of values that the UI will use for charts and other visualizations. To keep this straightforward, I am only printing the size of the Call vertex. The Call vertex is a list of values in the x_CallSummaryID vertex for the values the UI passed to the query. Another way to put it, once I know what values (YearMonth, LOB, Site & HealthSystem) I need to perform various calculations on, I need to filter the x_CallSummaryID vertex. From here I can begin my calculations because all the data points I need are connected to x_CallSummaryID.
Problem
On line 46, I know what values to execute the calculations (line 48 - 71) for. The next step is for me to filter the x_CallSummaryID vertex so I can start calculating data points. This is the slowest part of the query. If the query runs with no parameters then it will run very fast because it skips lines 50-68. For every IF statement that has to run, the execution time drastically increases. I have been unable to figure out how to filter x_CallSummaryID within a reasonable execution time. For the query below, if I run the query with only apply=TRUE, it will execute in around 75ms. If I run the query with 1 parameter, the best execute times I’ve gotten is around 1500 ms (1 small HealthSystem) but filtering for 1 YearMonth typically takes around 5000 ms. When adding 3 or more filters the query will take between 10000 and 15000 ms. For what I’m trying to accomplish in this query, I would imagine execution under 500 ms would be reasonable. With expectations of significant data growth I would prefer the execution time to be under 100 ms not matter what parameters are being used.
We are currently on v2.4.1 on a standalone server. I am using SYNTAX v2 because I’ve been attempting to use multi hops but haven’t had any luck.
1 CREATE QUERY Metrics(SET HS,SET YM, SET LOB,SET SITE, BOOL apply=False) FOR GRAPH SDD SYNTAX v2{
2 SetAccum @@hs, @@ym, @@lob, @@site;
3
4 ym = {x_YearMonth.};
5 hs = {x_HealthSystem.};
6 lob = {x_LOB.};
7 site = {x_Site.};
8
9 IF COUNT(YM) > 0 THEN ym = SELECT t FROM ym:t WHERE t.yearMonth IN YM ACCUM @@ym += t.yearMonth; END;
10 IF COUNT(HS) > 0 THEN hs = SELECT t FROM hs:t WHERE t.healthSystem IN HS ACCUM @@hs += t.healthSystem; END;
11 IF COUNT(LOB) > 0 THEN lob = SELECT t FROM lob:t WHERE t.lob IN LOB ACCUM @@lob += t.lob; END;
12 IF COUNT(SITE) > 0 THEN site = SELECT t FROM site:t WHERE t.site IN SITE ACCUM @@site += t.site; END;
13
14 IF COUNT(YM) == 0 THEN
15 ym_hs = SELECT x FROM hs:t-(x_HEALTHSYSTEM_YEARMONTH>:e)-x_YearMonth:x;
16 ym_lob = SELECT x FROM lob:t-(x_LOB_YEARMONTH>:e)-x_YearMonth:x;
17 ym_site = SELECT x FROM site:t-(x_SITE_YEARMONTH>:e)-x_YearMonth:x;
18 ym = ym_hs INTERSECT ym_lob INTERSECT ym_site;
19 ym = SELECT t FROM ym:t ACCUM @@ym += t.yearMonth;
20 END;
21
22 IF COUNT(HS) == 0 THEN
23 hs_ym = SELECT x FROM ym:t-(x_YEARMONTH_HEALTHSYSTEM>:e)-x_HealthSystem:x;
24 hs_lob = SELECT x FROM lob:t-(x_LOB_HEALTHSYSTEM>:e)-x_HealthSystem:x;
25 hs_site = SELECT x FROM site:t-(x_SITE_HEALTHSYSTEM>:e)-x_HealthSystem:x;
26 hs = hs_ym INTERSECT hs_lob INTERSECT hs_site;
27 hs = SELECT t FROM hs:t ACCUM @@hs += t.healthSystem;
28 END;
29
30 IF COUNT(LOB) == 0 THEN
31 lob_hs = SELECT x FROM hs:t-(x_HEALTHSYSTEM_LOB>:e)-x_LOB:x;
32 lob_ym = SELECT x FROM ym:t-(x_YEARMONTH_LOB>:e)-x_LOB:x;
33 lob_site = SELECT x FROM site:t-(x_SITE_LOB>:e)-x_LOB:x;
34 lob = lob_hs INTERSECT lob_ym INTERSECT lob_site;
35 lob = SELECT t FROM lob:t ACCUM @@lob += t.lob;
36 END;
37
38 IF COUNT(SITE) == 0 THEN
39 site_hs = SELECT x FROM hs:t-(x_HEALTHSYSTEM_SITE>:e)-x_Site:x;
40 site_ym = SELECT x FROM ym:t-(x_YEARMONTH_SITE>:e)-x_Site:x;
41 site_lob = SELECT x FROM lob:t-(x_LOB_SITE>:e)-x_Site:x;
42 site = site_hs INTERSECT site_ym INTERSECT site_lob;
43 site = SELECT t FROM site:t ACCUM @@site += t.site;
44 END;
45
46 PRINT @@hs, @@ym, @@lob, @@site;
47
48 IF apply == TRUE THEN
49 Calls = {x_CallSummaryID.*};
50 IF COUNT(HS) > 0 THEN
51 x_Calls = SELECT c FROM hs:s-(x_HEALTHSYSTEM_CALLSUMMARYID>:e)-x_CallSummaryID:c;
52 Calls = Calls INTERSECT x_Calls;
53 END;
54
55 IF COUNT(YM) > 0 THEN
56 x_Calls = SELECT c FROM ym:s-(x_YEARMONTH_CALLSUMMARYID>:e)-x_CallSummaryID:c;
57 Calls = Calls INTERSECT x_Calls;
58 END;
59
60 IF COUNT(LOB) > 0 THEN
61 x_Calls = SELECT c FROM lob:s-(x_LOB_CALLSUMMARYID>:e)-x_CallSummaryID:c;
62 Calls = Calls INTERSECT x_Calls;
63 END;
64
65 IF COUNT(SITE) > 0 THEN
66 x_Calls = SELECT c FROM site:s-(x_SITE_CALLSUMMARYID>:e)-x_CallSummaryID:c;
67 Calls = Calls INTERSECT x_Calls;
68 END;
69
70 PRINT Calls.size();
71 END;
72 }
Graph Size
Thank You,
Nick