
An error occurred When I run the following code to load my data into the database
directory = r'load_data/GSOurban/'
for dataFile in os.scandir(directory):
if dataFile.path.endswith(".csv"):
fileName = dataFile.name.split('.')[0]
print(fileName)
results = conn.uploadFile(dataFile, fileTag=fileName, jobName='load_vertex')
print(json.dumps(results, indent=2))
The error information is as follows
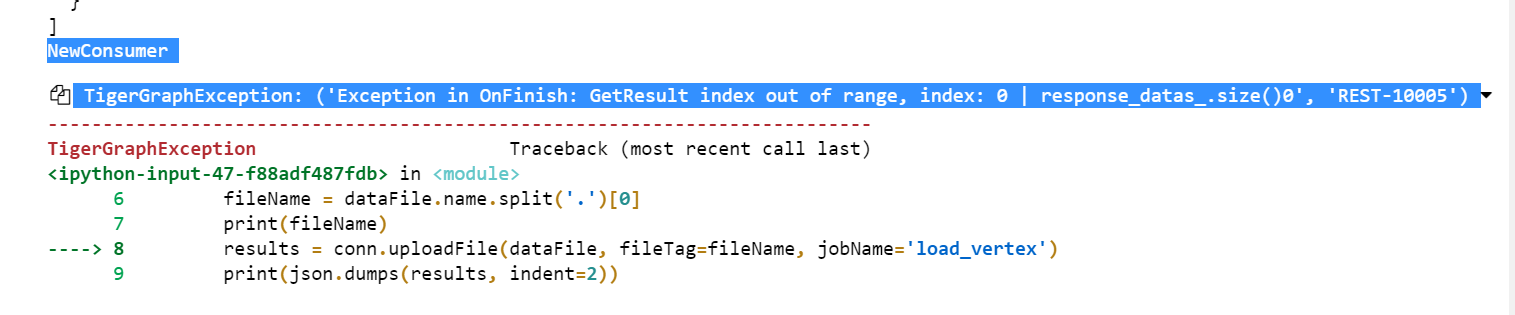
NewConsumer is my file name
vertex is defined as follows
CREATE VERTEX Consumer(
PRIMARY_ID id STRING,
Code STRING,
Phases INT,
NVolt_kV FLOAT,
DemP_kW FLOAT,
DemQ_kVAr FLOAT,
Pinst_kW FLOAT,
Qinst_kVAr FLOAT,
Yearly_kWh FLOAT,
NumCust INT,
longitude FLOAT,
latitude FLOAT)
and the content of the file is like this
this is load job code
DEFINE FILENAME NewConsumer;
LOAD NewConsumer TO VERTEX Consumer VALUES($0, $0, $1, $2, $3, $4, $7, $8, $9, $10, $11, $12)
USING header="true", separator=",";
I have carefully checked the file name, variable name, column name and column index number, and it seems that there is no problem
Several files in the folder have been loaded successfully, but the newconsumer prompts failure. I don’t know what the error message means. I want to know how to solve this error。
who can help me ![]()